
Зміст

Останнім часом можна все частіше зіткнутися з ситуацією, коли потрібно перевести будь-якої текст, що міститься на зображеннях, в електронну текстову форму. Для того щоб заощадити час і не передруковувати вручну, слід використовувати спеціальні комп'ютерні програми для розпізнавання тексту, про що ми і розповімо сьогодні.
Як оцифрувати текст
На ринку представлено чимало додатків для оцифровки тексту, тому кожен користувач знайде рішення, відповідне вимогам.
Спосіб 1: ABBYY FineReader
Це умовно-безкоштовний додаток від російського розробника володіє величезним функціоналом і дозволяє не тільки розпізнавати текст, але і виробляти його редагування, збереження в різних форматах і сканування паперових вихідних кодів.
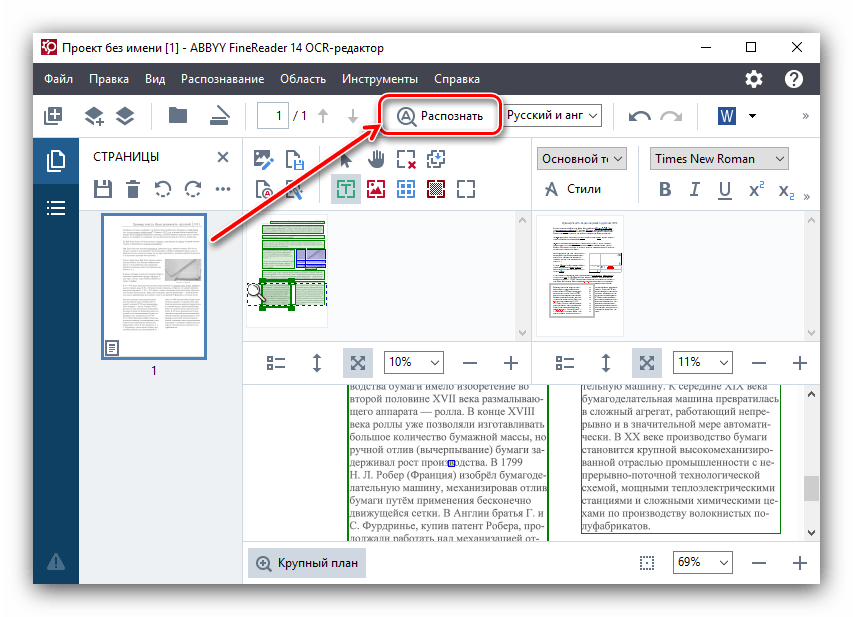
- Щоб розпізнати текст на зображенні, перш за все, потрібно завантажити її в програму. Для цього після запуску ABBYY FineReader тиснемо на кнопку «відкрити в OCR редакторі»
.
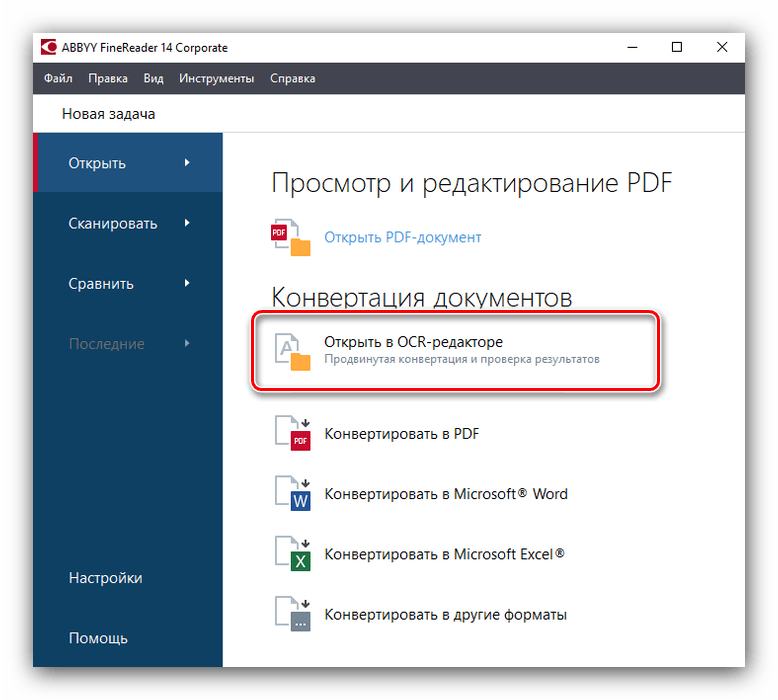
Після виконання даної дії відкривається вікно вибору джерела, де ви повинні знайти і відкрити потрібне зображення. Підтримуються такі популярні формати: JPEG, PNG, GIF, TIFF, XPS, BMP та ін., а також файли PDF і DjVU.
- Після завантаження в ABBYY FineReader автоматично починається процес розпізнавання тексту на зображенні без вашого втручання.
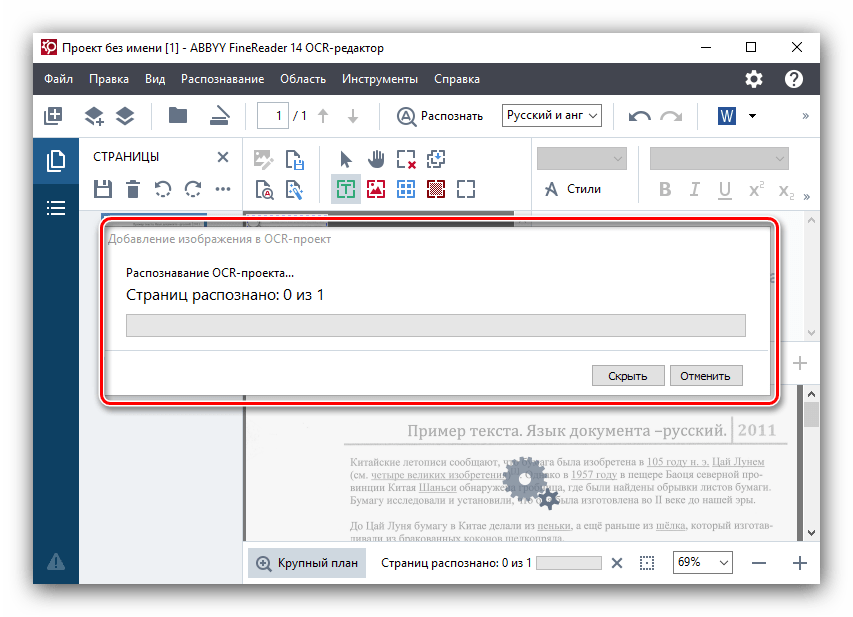
У разі якщо ви хочете зробити повторну процедуру розпізнавання, досить просто натиснути кнопку " розпізнати» у верхньому меню. - Іноді не всі символи програма може розпізнати коректно. Це може бути в тому випадку, якщо зображення на исходнике не дуже якісне, дуже дрібний шрифт, в тексті використовується кілька різних мов, застосовуються нестандартні символи. Але це не біда, так як помилки можна виправити вручну, за допомогою текстового редактора і набору інструментів, які в ньому містяться.
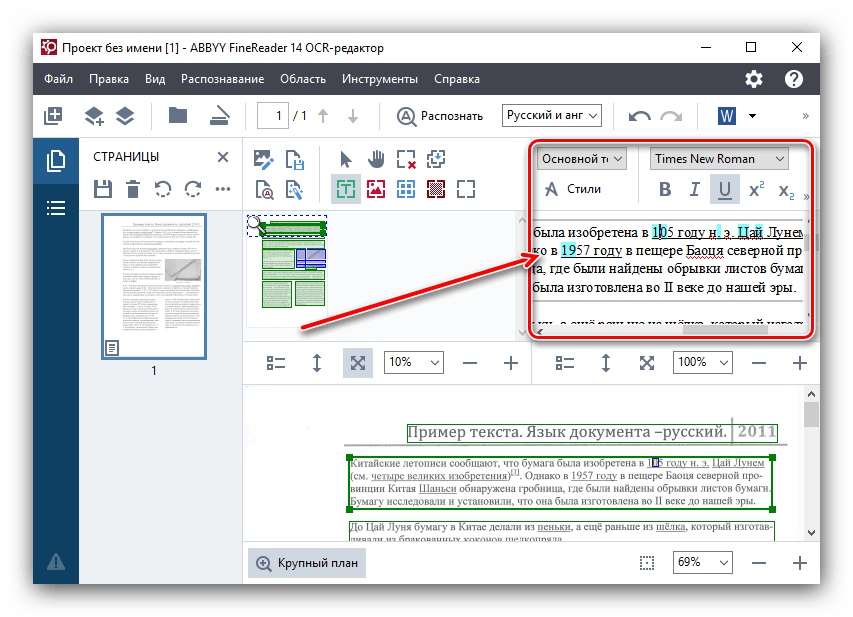
Для полегшення пошуку неточностей оцифровки програма за замовчуванням виділяє можливі помилки бірюзовим кольором.
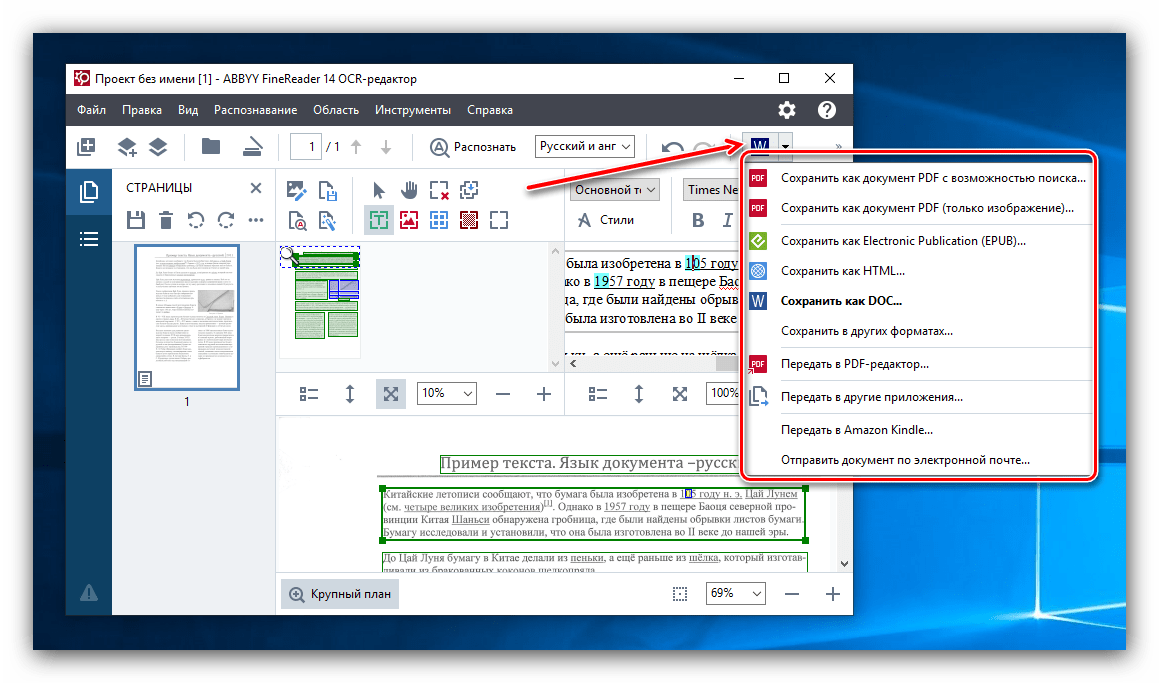
- Закономірним закінченням процесу розпізнавання є збереження його результатів. Для цього тиснемо кнопку " Зберегти» на верхній панелі меню. За замовчуванням вона має вигляд іконки старого логотипу Microsoft Word. Перед нами з'являється вікно, де можна самостійно визначити майбутнє місцезнаходження, в якому буде розташовуватися файл з розпізнаним текстом, а також його формат. Доступні наступні варіанти для збереження: DOC, DOCX, RTF, PDF, ODT, HTML, TXT, XLS, XLSX, PPTX, CSV, FB2, EPUB, DjVU.
ABBYY FineReader являє собою саме просунуте рішення, але однозначно рекомендувати саме його заважають платна модель поширення і обмеження пробної версії.
Спосіб 2: Readiris
Додаток Readiris зміцнилося на ринку як найближчий конкурент згаданого вище Файн рідер – воно надає подібний функціонал, деякі аспекти виконує дещо краще, ніж продукція ABBYY.
- Після запуску програми Виберіть джерело даних для оцифровки – зі сканера або ж з готового графічного файлу.
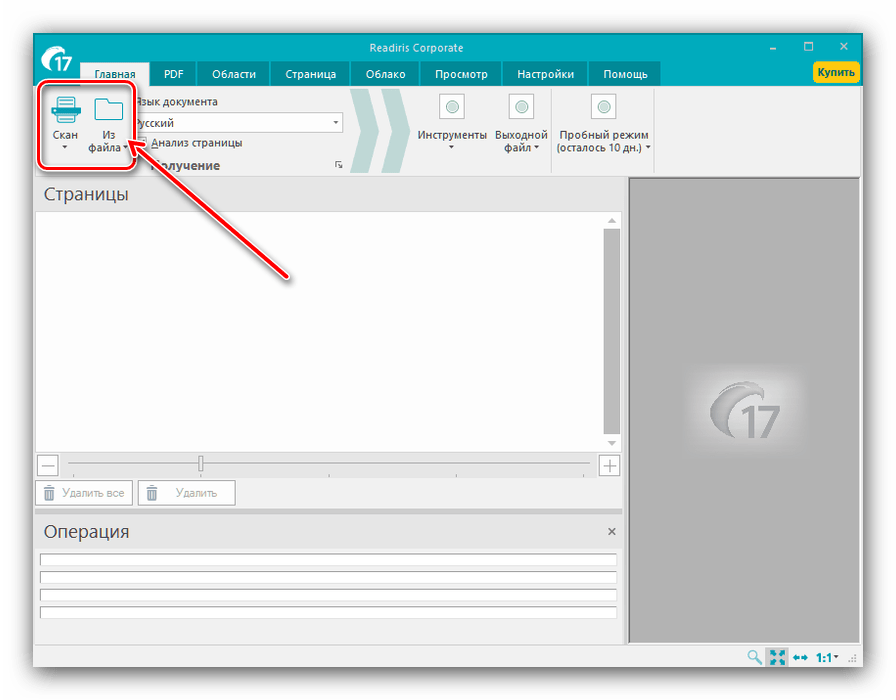
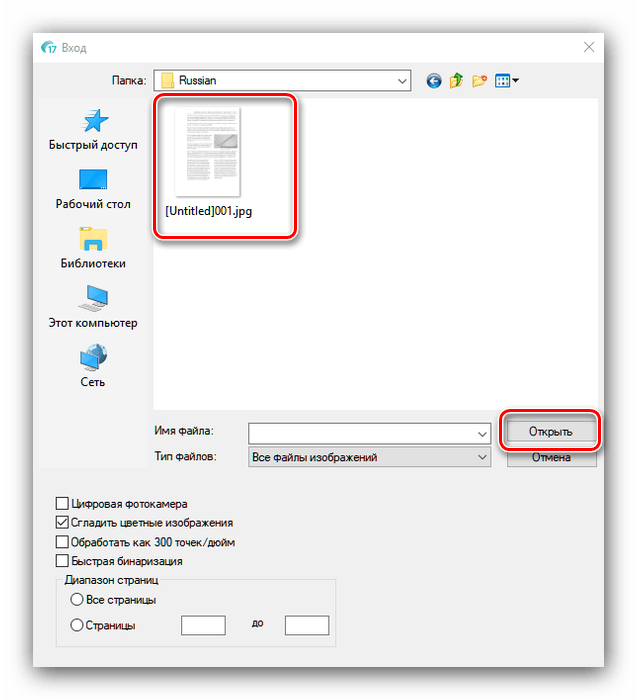
У прикладі ми будемо використовувати останній варіант-для нього слід скористатися кнопкою " з файлу» . - Відкриється діалогове вікно " провідника» , в якому слід вибрати потрібні документи. Підтримується більшість графічних форматів, а також PDF.
- Зачекайте, поки документ буде завантажений в програму, після чого слід налаштувати розпізнавання тексту. Насамперед потрібно встановити основну мову-виберіть його з меню, що випадає.
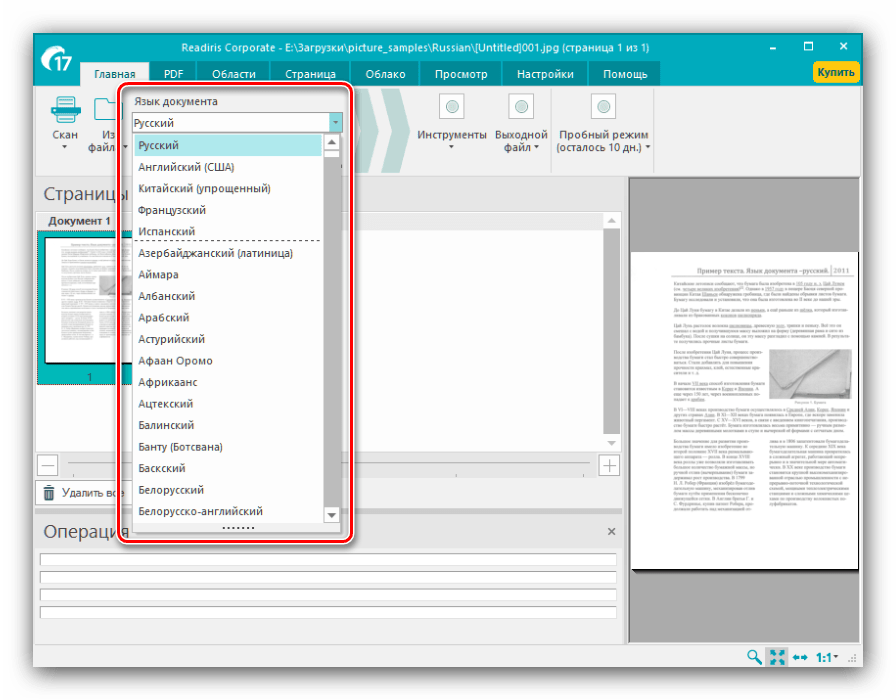
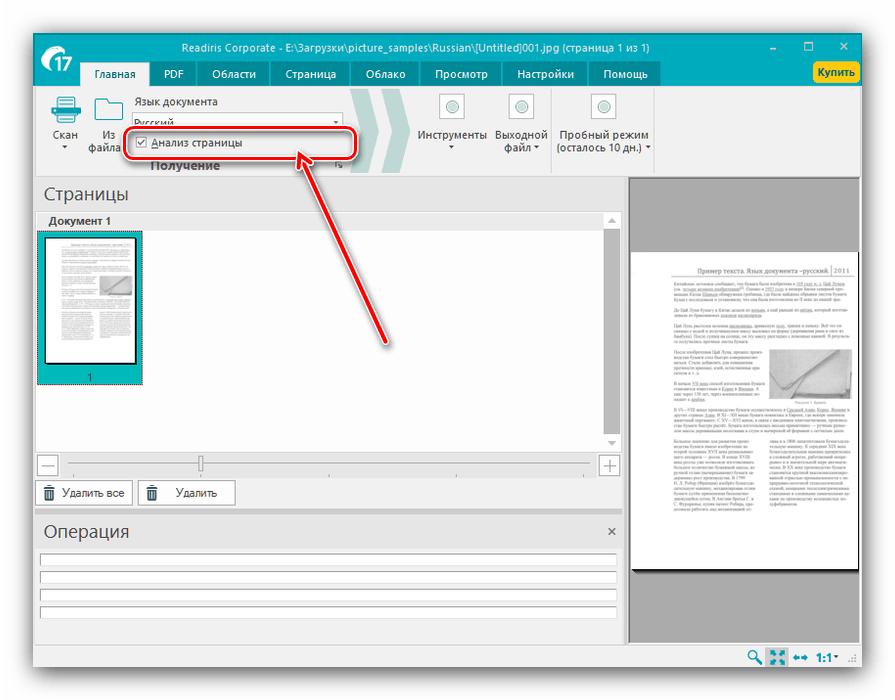
Також рекомендуємо відзначити опцію " аналіз тексту» , завдяки якій значно підвищитися якість оцифровки. - Далі зверніться до меню «інструменти»
&8212; наявні в ньому параметри допоможуть вирішити деякі проблеми сканування, такі як спотворення перспективи, недостатня контрастність картинки або зміщення тексту щодо полотна.
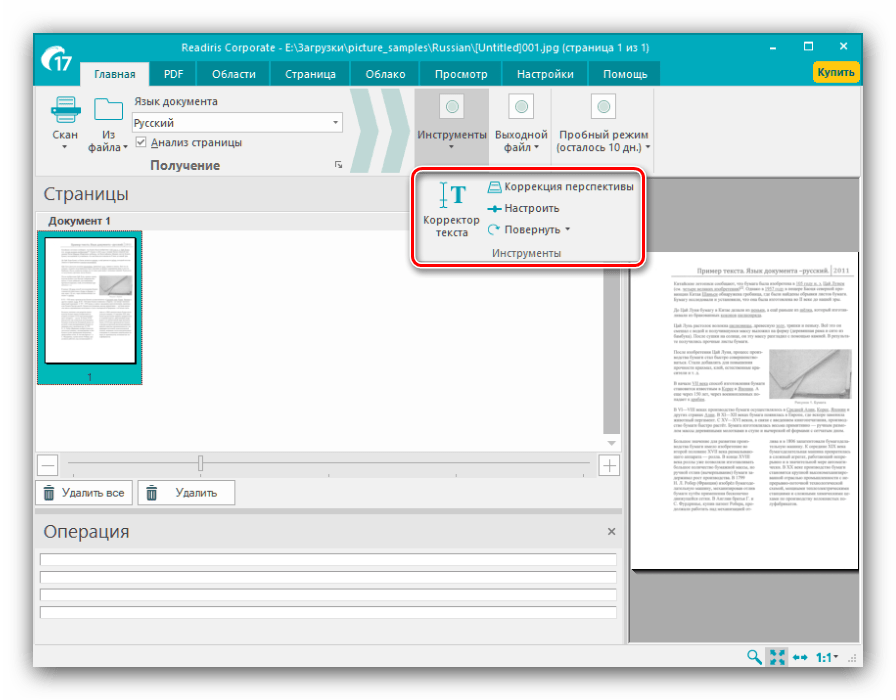
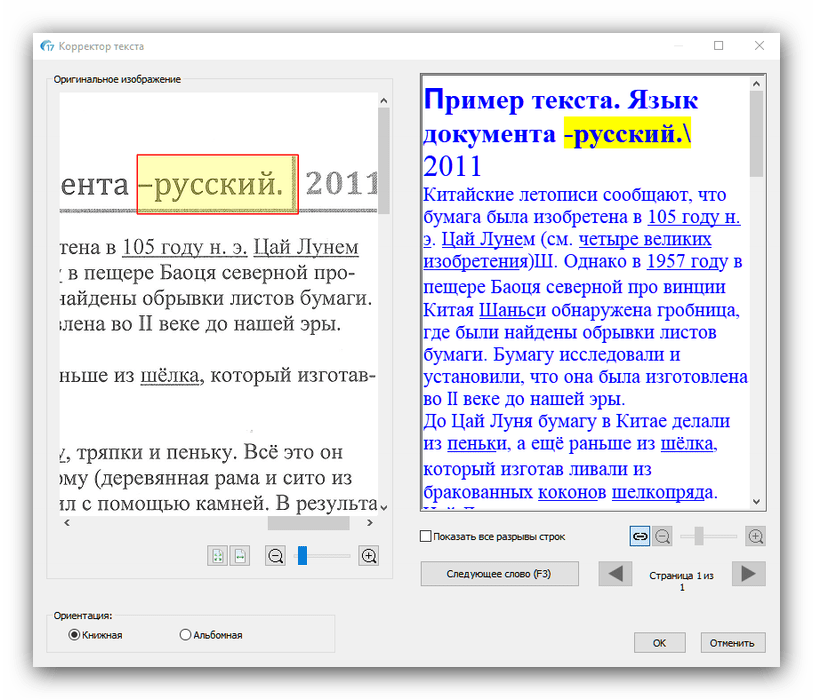
З цього меню також можна підкоригувати текст, якщо розпізнавання спрацювало неправильно. - Після внесення змін в розпізнаний текст слід задати вихідний формат отриманих даних через однойменне меню в панелі інструментів. Основними форматами вважаються PDF, а також файли Microsoft Office (DOCX і XLSX) – клікніть по необхідній позиції для вибору.
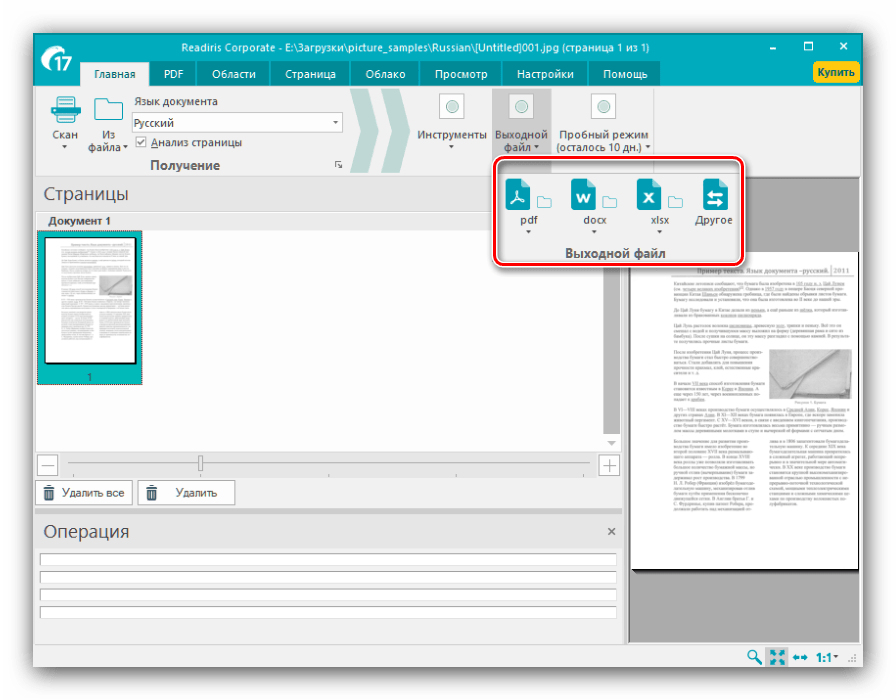
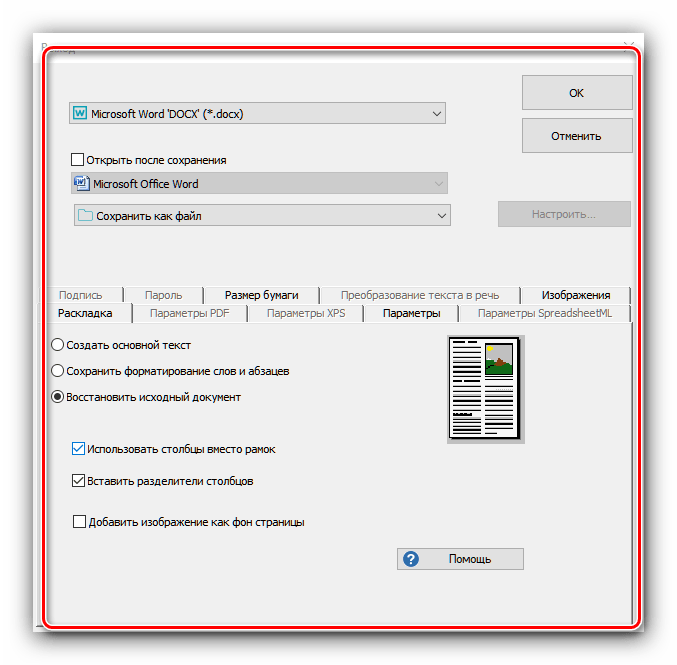
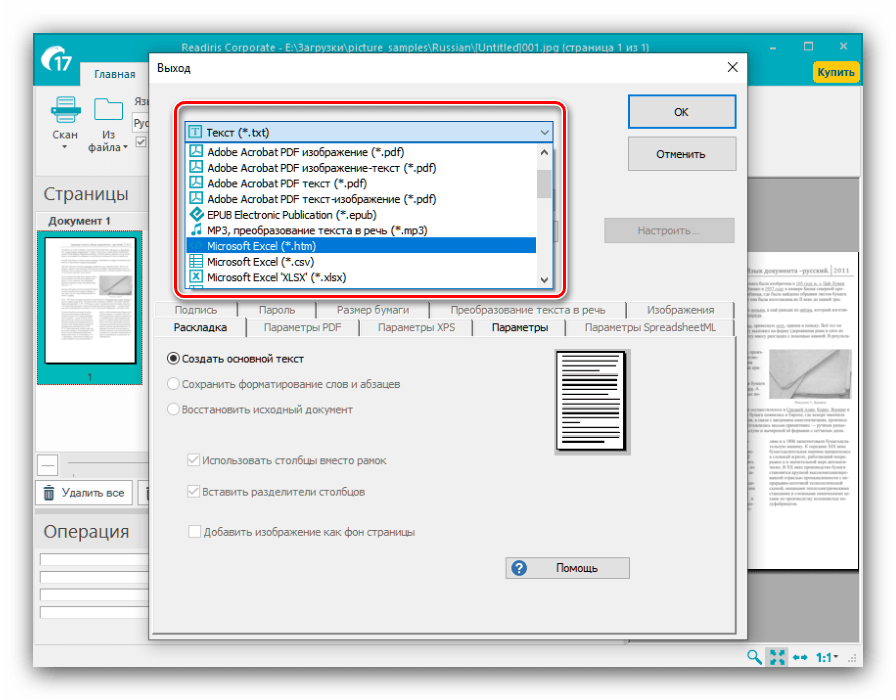
Всі можливі формати експорту згруповані в пункті " Інше» . Крім згаданих вище типів файлів, оцифрований текст можна зберегти у вигляді даних OpenOffice , гіпертекстових файлів або звичайних txt. - Після вибору формату відкриється віконце майстра з експорту. У ньому можна налаштувати ті чи інші параметри отриманого файлу (залежать від обраного формату) і варіант збереження (локальний або в хмарний сервіс). Після внесення всіх необхідних змін натисніть «ОК»
.
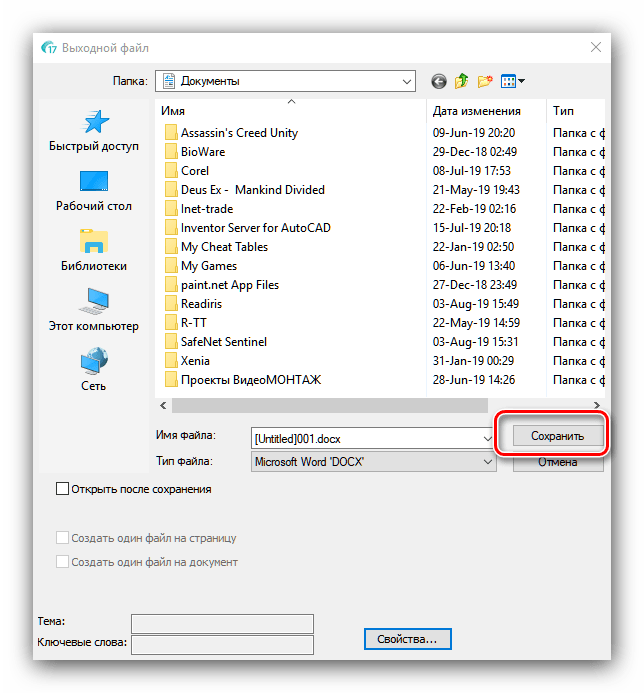
Знову з'явиться вікно " провідника» , в якому слід вибрати бажаний кінцевий каталог збереження.
В цілому Readiris являє собою зручне і сучасне рішення для оцифровки тексту, проте вагомим його недоліком можна назвати платну модель поширення.
Спосіб 3: RiDoc
Ще один додаток, орієнтоване на роботу зі сканерами, проте вміє працювати і з локальними файлами в різних форматах.
- Відкрийте додаток. Для початку роботи використовуйте на панелі інструментів кнопки»відкрити" або »Сканер" - перша відповідає за розпізнавання тексту в локальних файлах, друга дозволяє почати оцифровку одночасно зі скануванням. Для прикладу будемо використовувати перший варіант.
- У вікні " провідника» перейдіть до документа, з якого потрібно отримати текст, і виберіть його. Доступна також пакетна обробка документів.
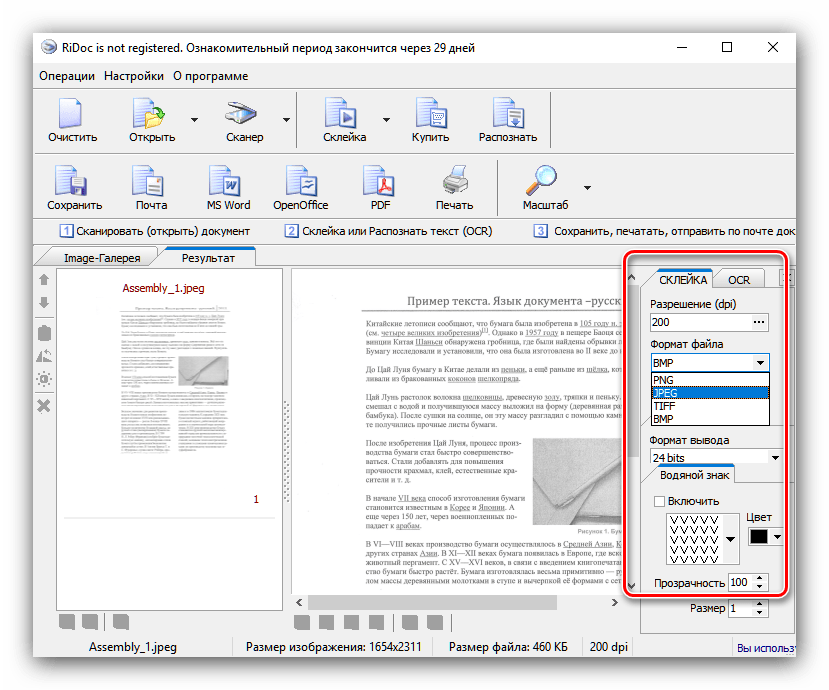
- Якщо потрібно, можна обробити отриманий файл: обрізати картинку, встановити область розпізнавання, виправити огріхи сканування.
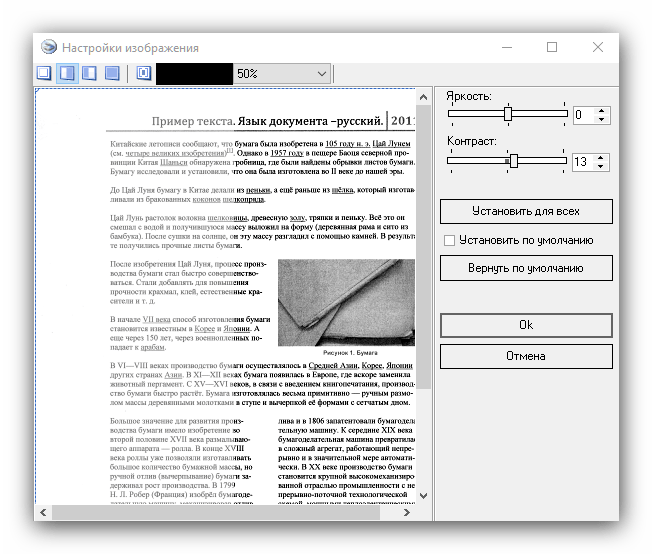
Окремим пунктом стоїть можливість склеювання-в цьому випадку мультісторінковий документ буде збережений єдиним файлом. Можна вибрати значення DPI та формат виводу (доступні лише файли зображень). - Для розпізнавання тексту в правій частині вікна знайдіть вкладку «OCR»
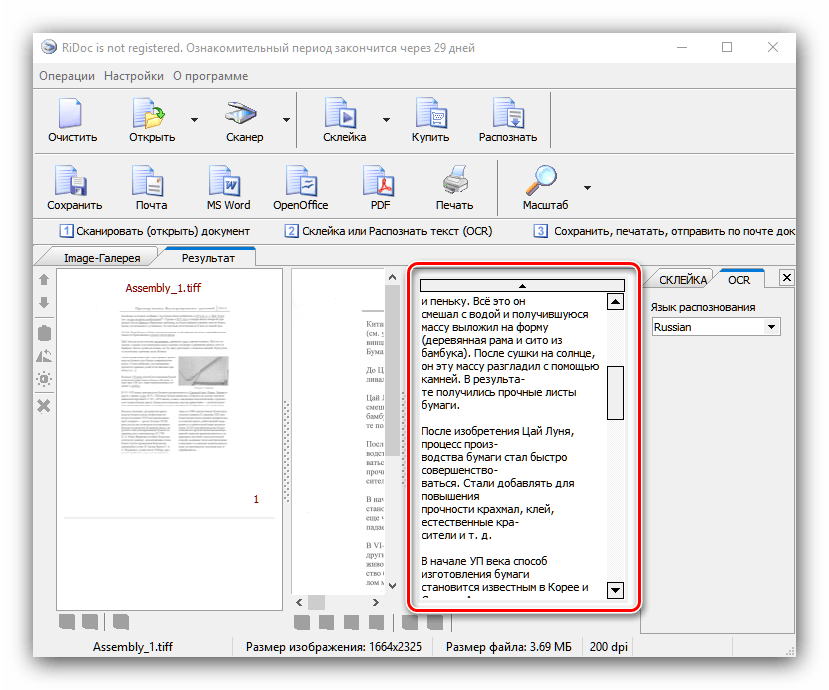
і відкрийте її. Доступних опцій не багато-можна вибрати тільки мову документа. Після зміни пакета натисніть на кнопку
" розпізнати»
на панелі інструментів.
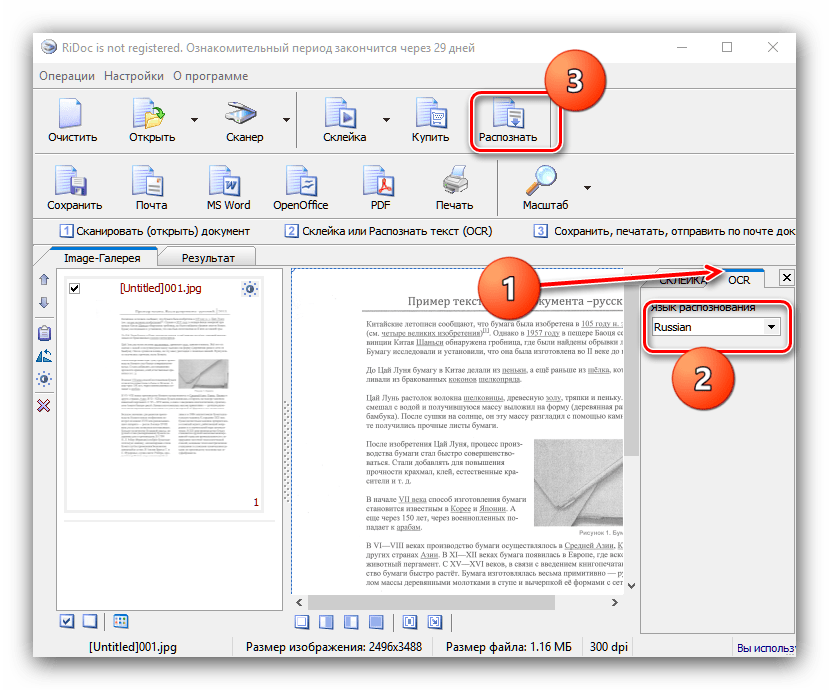
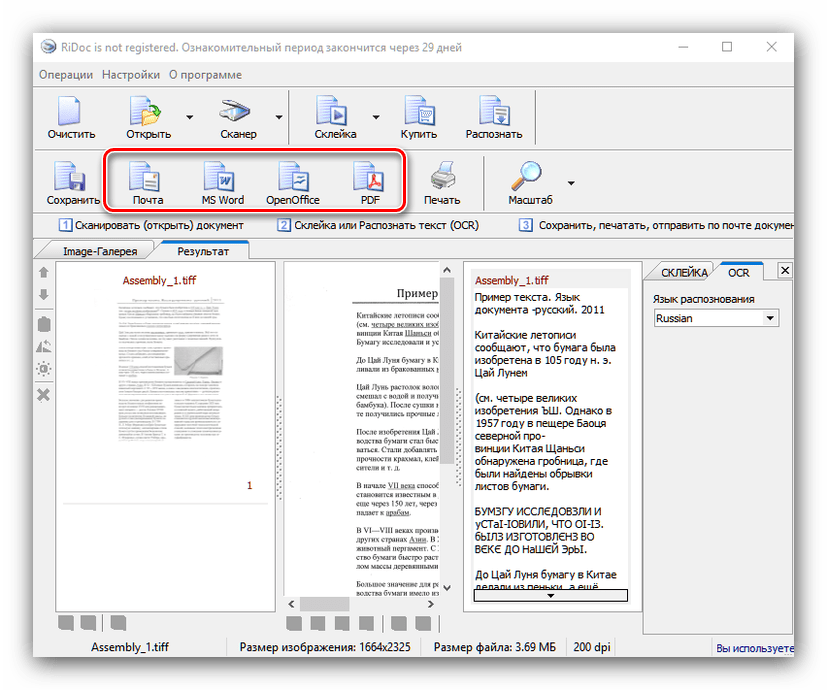
Звідси ж можна підправити результати оцифровки. - Збереження документів доступно в двох варіантах – пряме або експорт в офісні додатки. Для виконання першого способу слід використовувати кнопку " Зберегти»
. Відкриється вікно, в якому можна вибрати місце збереження, а також тип (одиничні файли або один багатосторінковий). Формат файлу, що зберігається залежить від обраного на етапі склейки.
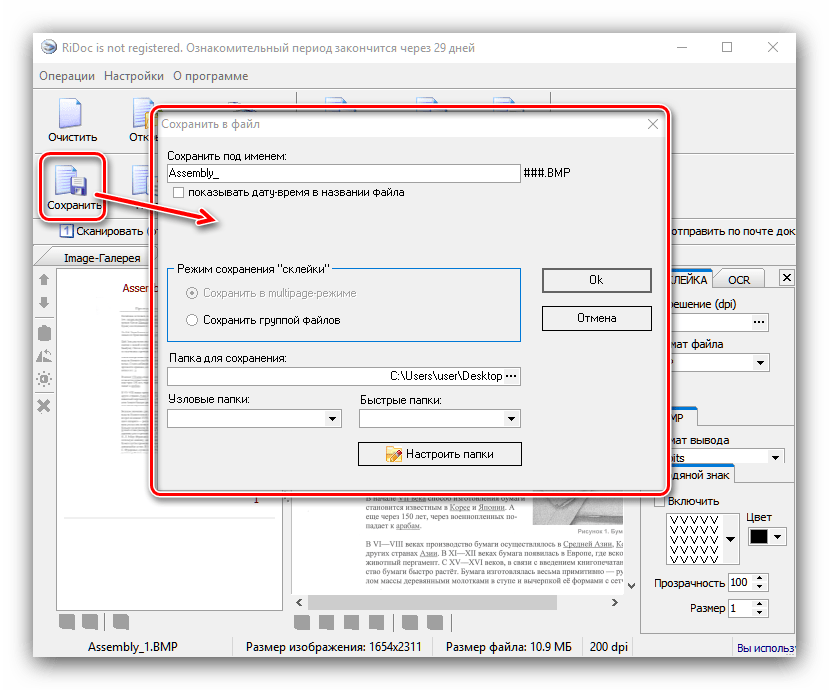
Експорт результатів можливий в текстові процесори офісних пакетів Microsoft або OpenOffice, у вигляді електронного листа (кнопка »пошта" ), в формат PDF або ж друку на принтері. Для експорту в офісні програми вони повинні бути встановлені на комп'ютері, тоді як збереження в ПДФ можливо навіть без відповідних додатків.
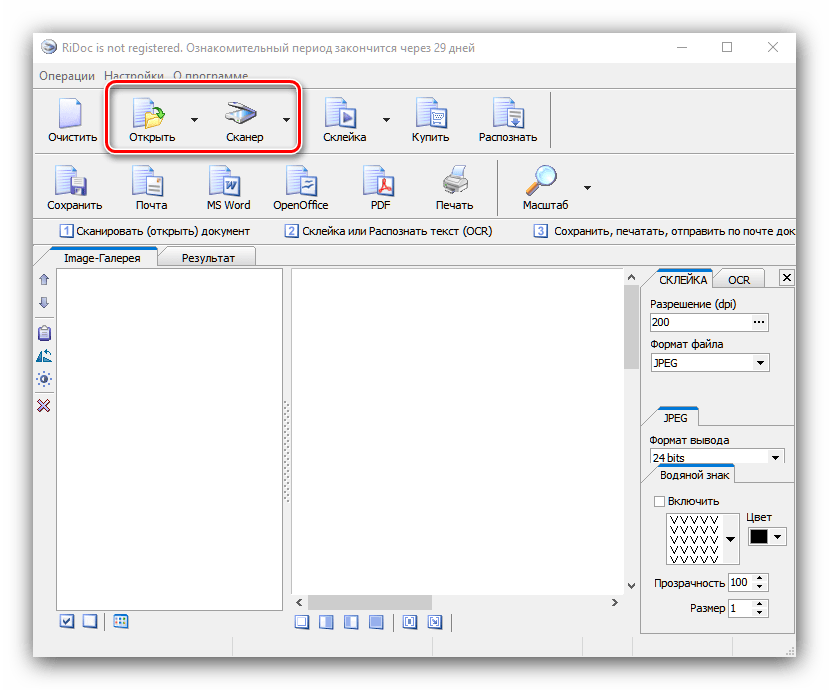
Як бачимо, Рідок являє собою небагате можливостями рішення, але для нескладних варіантів оцифровки цілком підійде.
Спосіб 4: Capture2Text
Невелика утиліта, яка дозволяє розпізнавати текст з будь-якої області на екрані комп'ютера, повністю безкоштовна і зручна у використанні.
Завантажте Capture2Text з офіційного веб-сайту
- Завантажте архів з програмою і розпакуйте його в будь-який зручний місце. Потім перейдіть до отриманого каталогу та запустіть виконуваний файл.
Далі відкрийте системний трей – в ньому повинна з'явиться іконка утиліти.
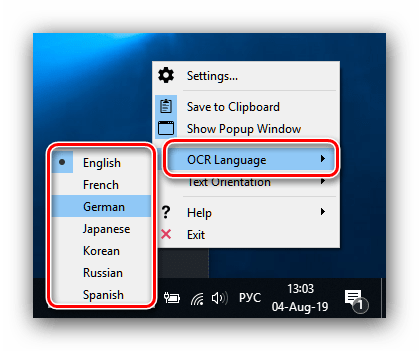
Для зміни мови розпізнавання клікніть правою кнопкою миші по значку Capture2Text в системному треї, потім в налаштуваннях виберіть пункт «OCR Language» і встановіть потрібну мову.
- Відкрийте файл, текст з якого потрібно оцифрувати, наприклад, документ DjVU без текстового шару. Коли файл буде відкритий, натисніть комбінацію клавіш Win+Q і виділіть область розпізнавання.
- З'явиться віконце утиліти з результатами розпізнавання. Отримані дані можна скопіювати в будь-який додаток, що підтримує введення користувальницького тексту.

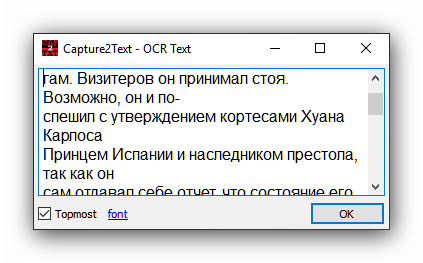
Додаток неймовірно просте, але це обертається обмеженим функціоналом і, часом, некоректним розпізнаванням російського тексту. Також до недоліків можемо віднести відсутність локалізації на російську мову. Втім, для деяких користувачів ці мінуси несуттєві, а основних можливостей буде цілком достатньо.
Спосіб 5: CuneiForm
Ще одне рішення для оцифровки тексту, створене на пострадянському просторі. Незважаючи на припинення розробки, все ще актуально.
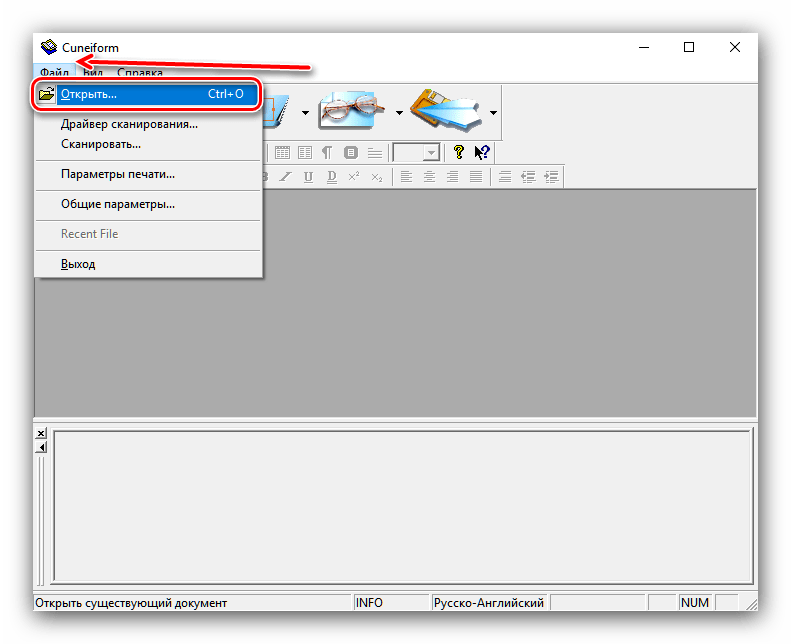
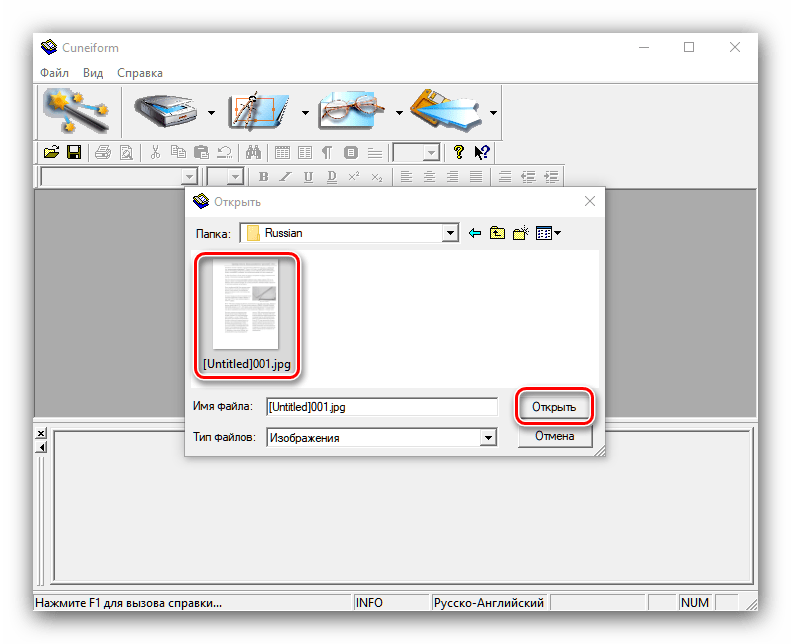
- Як і багато інших представлені в цій статті програми, КунейФорм вміє працювати як з готовими зображеннями, так і отримувати дані безпосередньо зі сканера. Скористаємося першим варіантом-для цього відкрийте меню»Файл" і виберіть в ньому пункт »відкрити" .
- За допомогою " провідника» виберіть потрібний файл або файли.
- Після завантаження даних у програму використовуйте пункти " розпізнавання»
-
«Авторозметка»
.
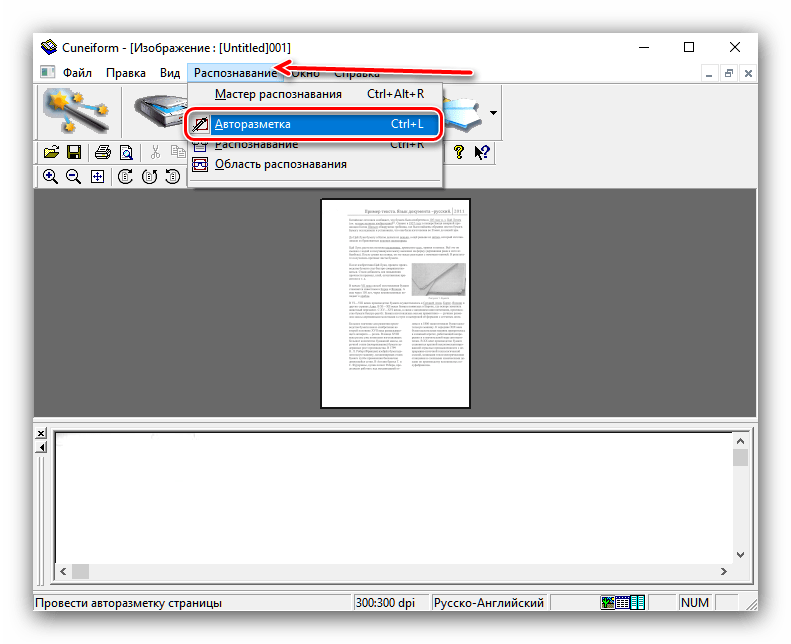
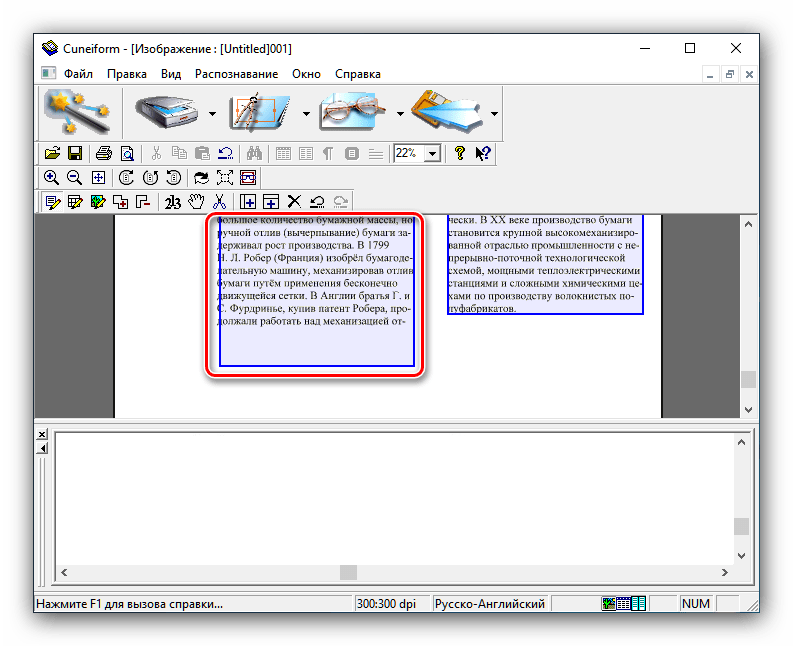
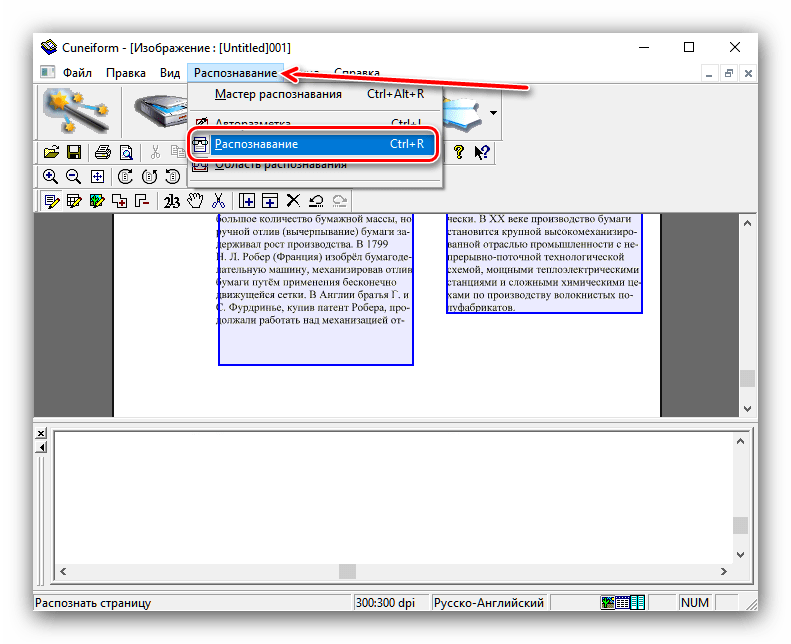
Це дозволить вибрати області з текстом для більш коректної роботи модуля OCR. Якщо автоматичні алгоритми неправильно розмітили сторінку, області з текстом можна підправити вручну або взагалі прибрати. - Далі можна займатися безпосередньо оцифруванням. Знову відкрийте меню " розпізнавання» і виберіть варіант з таким же найменуванням.
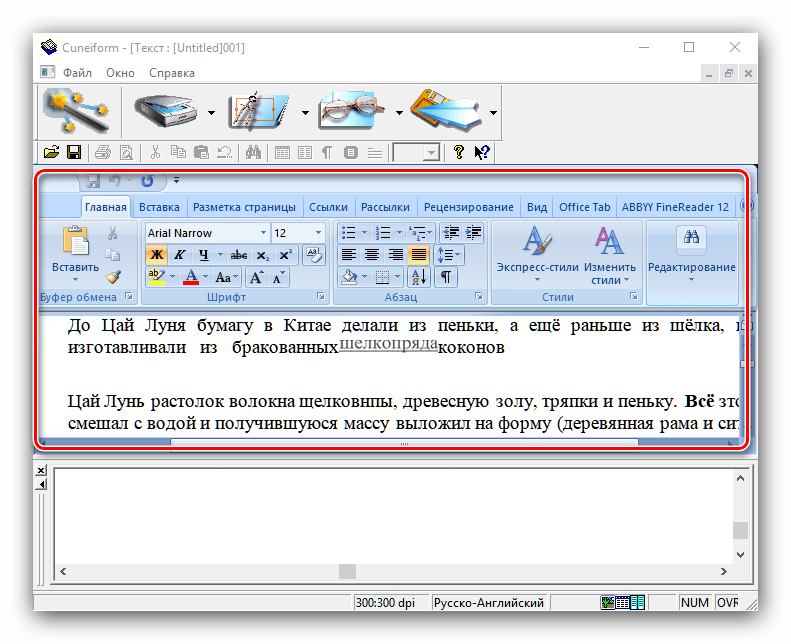
- Розпізнаний текст буде відкрито у вікні програми, де його також можна редагувати. Можливості досить великі, і відповідають повноцінному текстовому редактору. У разі якщо на комп'ютері встановлений MS Word, отримані дані будуть відкриті через його інтерфейс.
- Збереження результатів роботи доступно по пунктах»Файл"
-
" Зберегти»
.
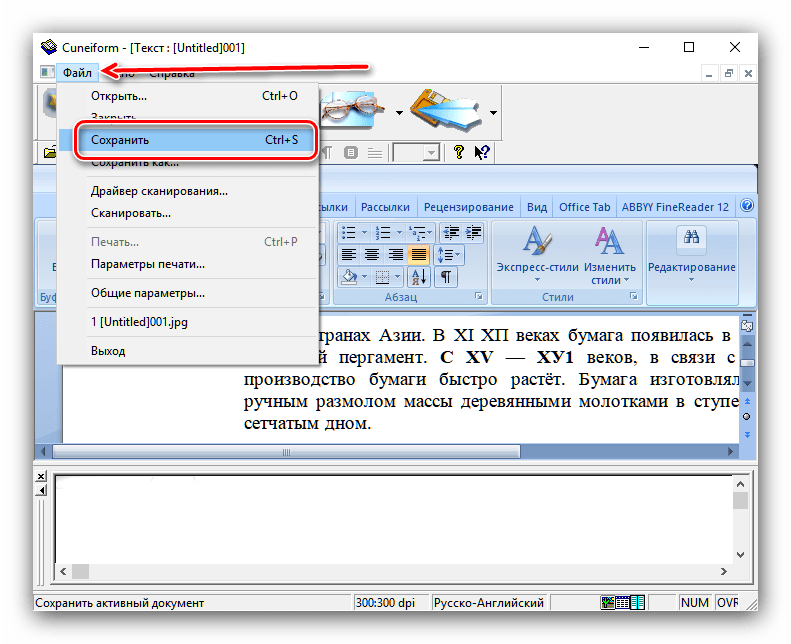
У відкритому " провіднику» виберіть розташування отриманого файлу та його формат. Підтримуються не багато варіантів: TXT, RTF, внутрішній формат FED, а також експорт в додатки Microsoft Office (Word і Excel).
Як бачимо, CuneiForm являє собою простий і в той же час потужний інструмент для оцифровки тексту. Вагомою його перевагою буде вільна модель поширення, проте недоліки у вигляді закінчення підтримки і відсутності формату PDF можуть змусити звернутися до альтернатив.
Висновок
Як бачимо, розпізнати текст з картинки досить просто, якщо використовувати для цього спеціалізовані додатки. Дана процедура не зажадає від вас багато зусиль, а користь буде у величезній економії часу.



