
Зміст

Витягти текст з PDF-файлу методом звичайного копіювання можна далеко не завжди. Часто сторінки подібних документів являють собою відсканований вміст їх паперових варіантів. Для перетворення таких файлів в повністю редаговані текстові дані використовуються спеціальні програми з функцією Optical Character Recognition (OCR).
Такі рішення є досить складними в реалізації і, отже, коштують чималих грошей. Якщо потреба в розпізнаванні тексту з PDF у вас виникає регулярно, цілком доцільно буде придбати відповідну програму. Для рідкісних же випадків більш логічним буде скористатися одним з доступних онлайн-сервісів з подібними функціями.
Як розпізнати текст за допомогою PDF в Інтернеті
Звичайно, набір можливостей онлайн-сервісів OCR, в порівнянні з повноцінними десктопними рішеннями, більш обмежений. Але і працювати з такими ресурсами можна або ж зовсім безкоштовно, або за символічну плату. Головне, що з основним своїм завданням, а саме з розпізнаванням тексту, відповідні веб-додатки справляються так само добре.
Спосіб 1: ABBYY FineReader Online
Компанія-розробник сервісу &8212; одна з лідерів в області оптичного розпізнавання документів. ABBYY FineReader для Windows і Mac є потужним рішенням для перетворення PDF в текст і подальшої роботи з ним.
Веб-аналог програми, звичайно ж, поступається їй по функціоналу. Проте сервіс вміє розпізнавати текст зі сканів і фотографій на більш ніж 190 мовах. Підтримується перетворення PDF-файлів в документи Word , Excel і т. п.
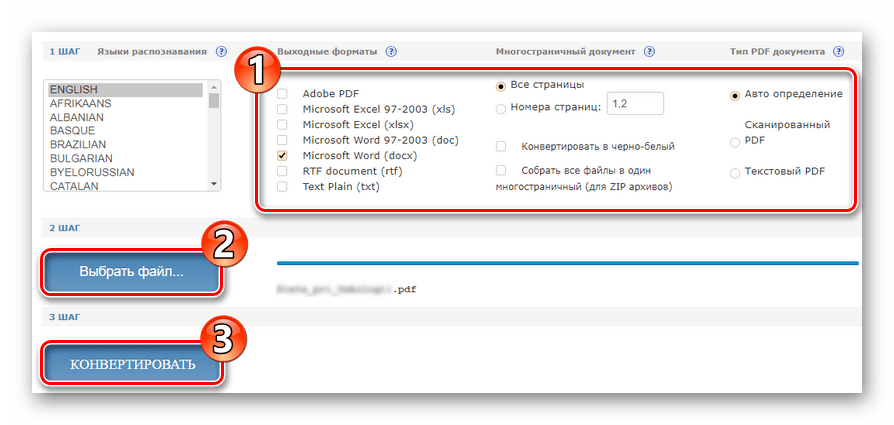
- Перш ніж приступити до роботи з інструментом, створіть аккаунт на сайті або увійдіть за допомогою облікового запису Facebook, Google або Microsoft.
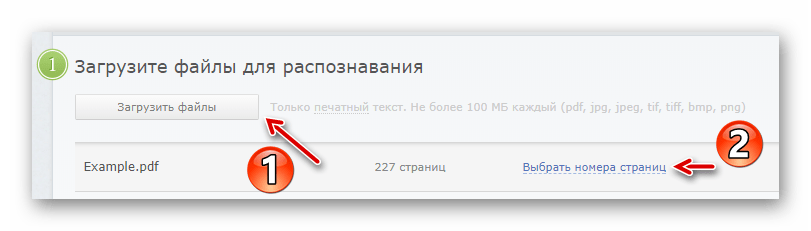
Щоб перейти до вікна авторизації, клацніть по кнопці &171;вхід&187; у верхній панелі меню. - Здійснивши вхід, імпортуйте потрібний PDF-документ в FineReader, скориставшись кнопкою &171; завантажити файли&187;
.
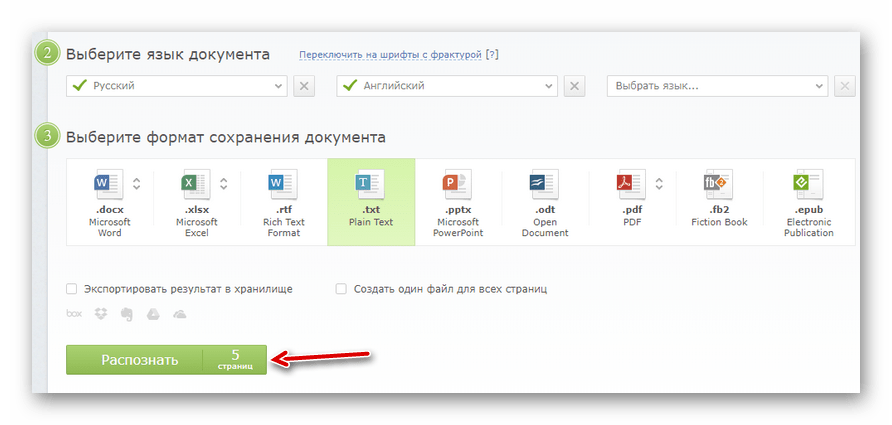
Потім натисніть & 171; вибрати номери сторінок & 187; і вкажіть бажаний проміжок для розпізнавання тексту. - Далі виберіть мови, присутні в документі, формат підсумкового файлу і натисніть на кнопку & 171; розпізнати&187;
.
- Після обробки, тривалість якої повністю залежить від обсягу документа, ви можете завантажити готовий файл з текстовими даними просто клацнувши по його назві.
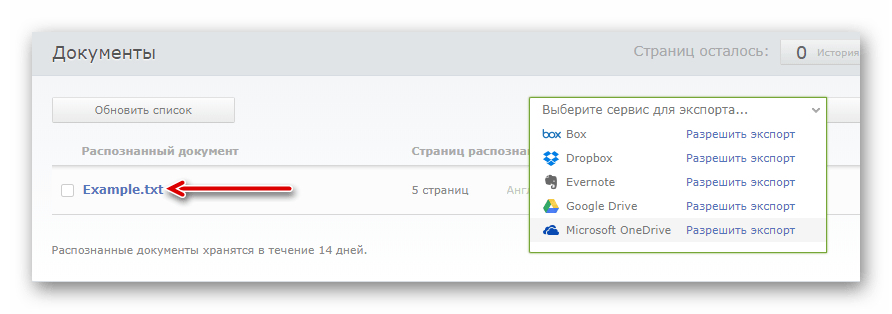
Або ж експортуйте його в один з доступних хмарних сервісів.
Сервіс відрізняється, ймовірно, найбільш точними алгоритмами розпізнавання тексту на зображеннях і PDF-файлах. Але, на жаль, його Безкоштовне використання обмежується п'ятьма обробленими сторінками на місяць. Щоб працювати з більш об'ємними документами, доведеться купити річну підписку.
Тим не менш, якщо функція OCR потрібна зовсім вже рідко, ABBYY FineReader Online &8212; відмінний варіант для вилучення тексту з невеликих PDF-файлів.
Спосіб 2: Free Online OCR
Простий і зручний сервіс для оцифровки тексту. Без необхідності реєстрації ресурс дозволяє розпізнавати 15 повних PDF-сторінок на годину. Free Online OCR повноцінно працює з документами на 46 мовах і без авторизації підтримує три формати експорту тексту &8212; DOCX, XLSX і txt.
При реєстрації Користувач отримує можливість обробляти багатосторінкові документи, проте безкоштовна кількість цих самих сторінок обмежена 50 одиницями.
- Щоб розпізнати текст з PDF як &171;гість&187;, без авторизації на ресурсі, скористайтеся відповідною формою на головній сторінці сайту.
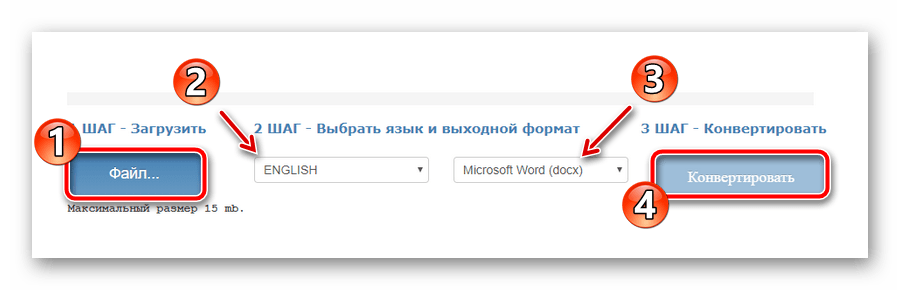
Виберіть потрібний документ за допомогою кнопки &171;Файл&187; , вкажіть основну мову тексту, вихідний формат, потім дочекайтеся завантаження файлу і натисніть &171; конвертувати & 187; . - Після закінчення процесу оцифрування натисніть & 171; завантажити вихідний файл&187;
для збереження готового документа з текстом на комп'ютері.
Для авторизованих же користувачів послідовність дій дещо інша.
- Скористайтеся кнопкою & 171; реєстрація&187;
або
& 171; вхід&187;
у верхній панелі меню, щоб, відповідно, створити обліковий запис Free Online OCR або зайти в неї.
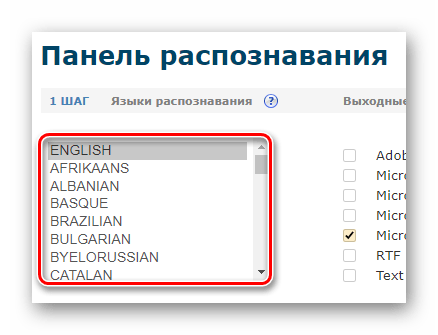
- Після авторизації в панелі розпізнавання, утримуючи клавішу &171;CTRL&187;
, виберіть до двох мов вихідного документа із запропонованого списку.
- Вкажіть подальші параметри вилучення тексту з PDF і натисніть кнопку &171;Виберіть файл&187;
для завантаження документа в сервіс.
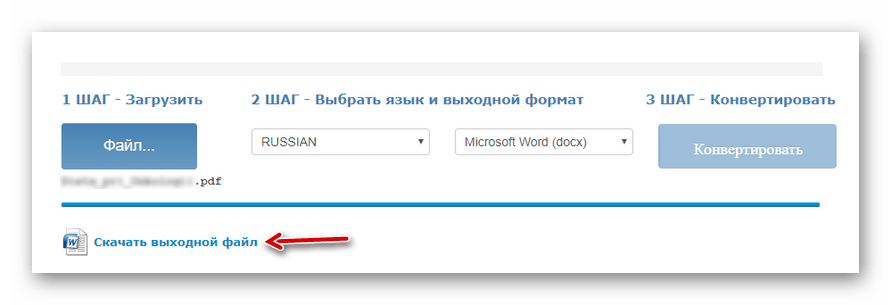
Потім, щоб приступити до розпізнавання, клацніть & 171; конвертувати & 187; . - Після закінчення обробки документа натисніть на посилання з назвою вихідного файлу у відповідній колонці.
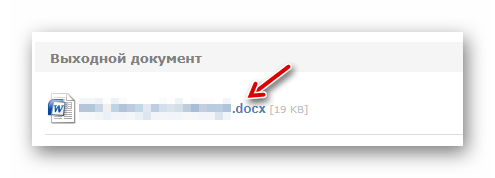
Результат розпізнавання відразу ж буде збережений в пам'яті вашого комп'ютера.
При необхідності витягти текст з невеликого PDF-документа можна сміливо вдаватися до використання вищеописаного інструменту. Для роботи ж з об'ємними файлами доведеться купити додаткові Символи під Free Online OCR або ж вдатися до іншого рішення.
Спосіб 3: NewOCR
Повністю безкоштовний OCR-сервіс, що дозволяє витягувати текст практично з будь-яких графічних і електронних документів на кшталт DjVu і PDF. Ресурс не накладає обмежень на розмір і кількість розпізнаваних файлів, не вимагає реєстрації і пропонує широкий набір супутніх функцій.
NewOCR підтримує 106 мов і вміє коректно обробляти навіть низькоякісні скани документів. Є можливість вручну вибирати область для розпізнавання тексту на сторінці файлу.
- Так, приступити до роботи з ресурсом ви можете відразу, без необхідності виконання зайвих дій.
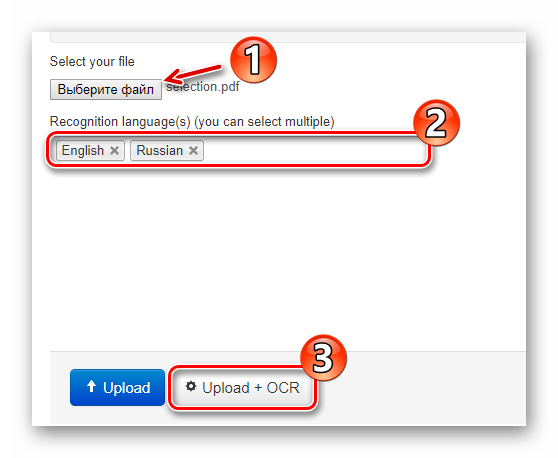
Прямо на головній сторінці розміщена форма для імпорту документа на сайт. Щоб завантажити файл в NewOCR, скористайтеся кнопкою &171;Виберіть файл&187; у розділі &171;Select your file&187; . Потім у полі &171;Recognition language(s)&187; вкажіть один або більше мов вихідного документа, після чого натисніть &171;Upload + OCR&187; . - Задайте бажані налаштування розпізнавання, виберіть потрібну сторінку для вилучення тексту і клацніть по кнопці &171;OCR&187;
.
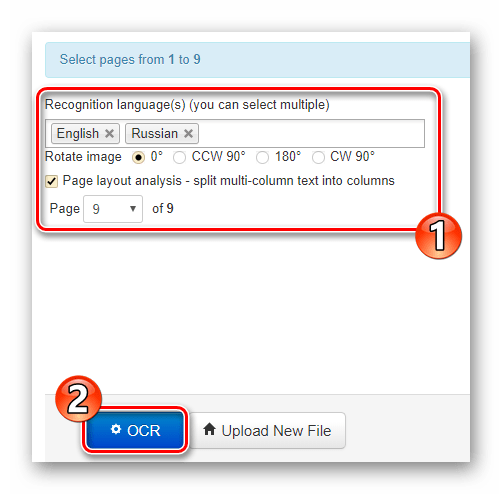
- Прокрутіть сторінку трохи нижче та знайдіть кнопку &171;Download&187;
.
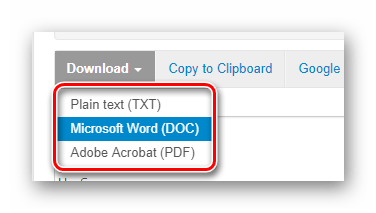
Клацніть по ній і в випадаючому списку виберіть необхідний формат документа для скачування. Після цього готовий файл з витягнутим текстом буде завантажений на ваш комп'ютер.
Інструмент зручний і досить якісно розпізнає всі символи. Втім, обробку кожної сторінки імпортованого PDF-документа потрібно запускати самостійно і виводиться вона в окремий файл. Можна, звичайно, відразу копіювати результати розпізнавання в буфер обміну і об'єднувати їх з іншими.
Проте, з огляду на вищеописаний нюанс, великі обсяги тексту за допомогою NewOCR витягувати досить важко. З малими ж файлами сервіс справляється & 171; на ура&187;.
Спосіб 4: OCR.Space
Простий і зрозумілий ресурс для оцифровки тексту, дозволяє розпізнавати PDF-документи і виводити результат в TXT-файл. Ніяких лімітів за кількістю сторінок не передбачено. Єдине обмеження &8212; розмір вхідного документа не повинен перевищувати 5 мегабайт.
- Реєструватися для роботи з інструментом не потрібно.
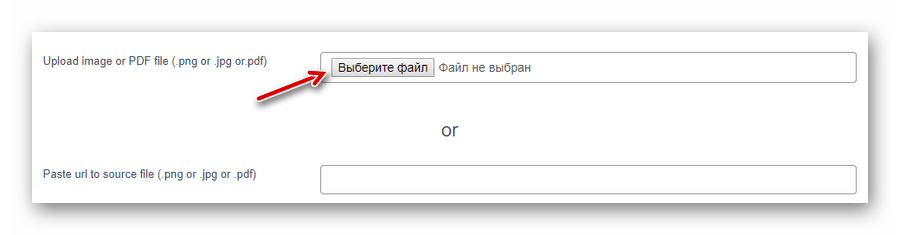
Просто перейдіть за посиланням вище і завантажте PDF-документ на сайт з комп'ютера за допомогою кнопки &171; Виберіть файл&187; або з мережі &8212; за посиланням. - У випадаючому списку &171;Select OCR language&187;
виберіть мову імпортованого документа.
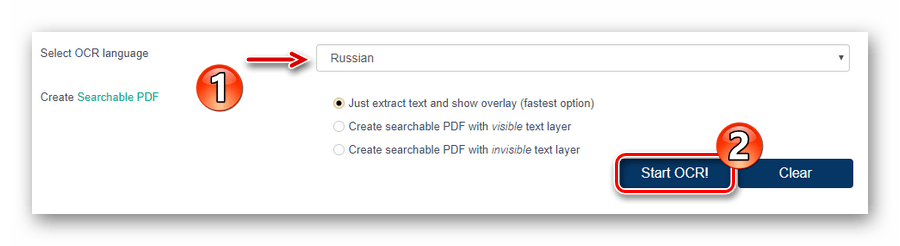
Потім запустіть процес розпізнавання тексту, натиснувши кнопку &171;Start OCR!&187; . - Після закінчення обробки файлу ознайомтеся з результатом в поле &171;OCR&8217;ed Result&187;
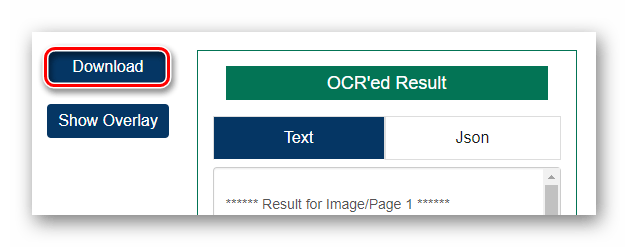
і натисніть
&171;Download&187;
, щоб завантажити готовий txt-документ.
Якщо вам потрібно просто витягти текст з PDF і при цьому фінальне його форматування зовсім не важливо, OCR.Space & 8212; хороший вибір. Єдине, документ повинен бути&171; одномовним & 187;, так як розпізнавання двох і більше мов одночасно в сервісі не передбачено.
Читайте також: безкоштовні аналоги FineReader
Оцінюючи онлайн-інструменти, представлені в статті, слід зазначити, що найбільш точно і якісно з функцією OCR справляється FineReader Online від ABBYY. Якщо для вас важлива саме максимальна точність розпізнавання тексту, найкраще розглянути конкретно цей варіант. Але і заплатити за нього, швидше за все, також доведеться.
Якщо ж потрібна оцифровка невеликих документів і ви готові самостійно виправляти помилки за сервісом, доцільно використовувати NewOCR, OCR.Space або Free Online OCR.



